
Challenge
In 2019, Concord Resources Limited (Concord), a leading global trader of metals and minerals, came to us for help. They needed to calculate the carbon intensity and footprint of their supply chains, across their entire trade portfolio (~10,000 trades annually).
To provide Concord with fast, accurate supply chain (Scope 3) carbon accounting, we needed a way to digitally model these trades and enable automated emissions calculations.
The key challenge: how to automatically map 10,000 trades to a digital form, to compute their emissions and quantify performance?
Approach
Spotting supply chain data gaps
For these types of commodity trades, we’re primarily interested in three sources of emissions:
- Production emissions: the 'cradle-to-gate' emissions for the product being traded, such as Copper Cathode. Since the emissions of the product vary widely based upon where it’s made, determining the production asset is the most critical step in the accounting process.
- Asset to Port emissions: emissions from the transport of the product from where it was made to the port from which it was shipped.
- Port to Port emissions: the emissions from transporting the product to its destination.
At the destination, trades are typically deposited in a warehouse close to the port, producing negligible emissions.
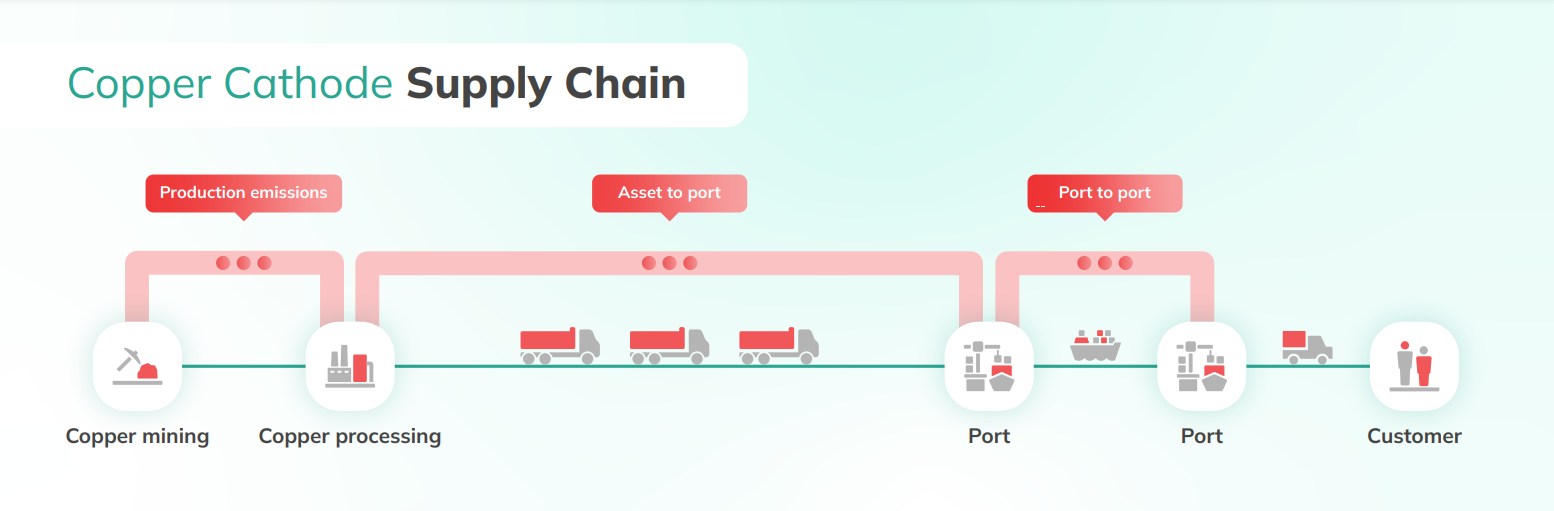 The number of ports involved in commodity trades globally is relatively limited. Mapping from the client’s port list to our own database of ~100,000 ports was straightforward. Combined with representative vessels from our shipping database (87,000 ships), this allowed us to calculate Port to Port emissions relatively easily.
The number of ports involved in commodity trades globally is relatively limited. Mapping from the client’s port list to our own database of ~100,000 ports was straightforward. Combined with representative vessels from our shipping database (87,000 ships), this allowed us to calculate Port to Port emissions relatively easily.
Identifying the production asset, however, was a formidable challenge.
Using machine learning to identify brand
Most of the metals we’re interested in are traded on the London Metals Exchange (LME), and allocated a Brand. This is a commonly used term which describes where the product was made. The LME maintains a list of valid brands, all of which are guaranteed to match a certain quality standard. When traders buy LME-branded aluminum, for example, they know they’re getting an equivalent product, wherever in the world it comes from.
Of course, in reality these products are not at all equivalent in terms of the emissions incurred in their production. Distinguishing between different brands is thus a critical step in assessing the emissions of a trade.
Most brands map to one or a few assets. Once we know the brand, we can identify the production asset and estimate the production emissions. The brand is not explicitly identified in the information about the trade we get from Concord, but it does contain several clues as to the likely brand:
- The port from which the product was shipped
- The supplier of the product
- An extended name of the product
- Additional notes on the product
The mapping from these 4 fields to a specific asset is complex. For instance, some product names will explicitly quote the brand (brand = Vedanta):
Product: Aluminium 6063 06 Extrusion 228'' 8" Vedanta
On other occasions, ports are situated next to a particular asset, and the brand takes the name of the port (brand = Delfzijl):
Port: Delfzijl
And sometimes particular suppliers trade in particular brands (brand = Hindalco):
Supplier: Hindalco Ind
Other trades combine a variety of hints, such as particular combination of product, supplier, and port. With such a variety of hints, writing a set of manual mapping rules wasn’t feasible. Natural language processing was an obvious fit.
Modelling the brand
In 2019, we’d already painstakingly manually labelled around ~3,300 examples. Using this data, we trained a variety of machine learning models to classify each trade according to brand.
With any natural language processing task, preprocessing is key. Since most of the terms we were looking for were proper nouns not typically included in the corpus of typical NLP models, pretrained word embeddings were of little use.1
Instead, we focused upon binary features that signified the presence or absence of particular terms in a variety of fields. For instance, for every brand we constructed an inverted index, mapping components and common rephrasing of the brand name to the brand:
Brand name: UAZ SUAL
Inverted index:
UAZ -> UAZ SUAL
SUAL -> UAZ SUAL
UAZ SUAL -> UAZ SUAL
UAZ-SUAL -> UAZ SUAL
We then used this index to scan several of the free-text columns in Concord's trade logs, accumulating hits for different brands and then constructing a bag-of-words representation based upon how frequently different brands were mentioned in a trade’s representation, e.g.
MOZAL-B : 0
MOZAL-A : 0
HINDALCO: 0
VEDANTA: 2
This, combined with a categorical representation of the trade’s supplier, origin, destination, and product yielded performance of ~96% on the test set.
Ambiguous brands
Some trades simply lack enough information to determine the brand or asset from which the material was sourced. In such cases, we have to fallback to lower resolution emission estimates, asking first:
- Can we identify the company operating the asset? Sometimes this is identifiable from the trade, even if the asset is not. If so, we use a company average emission factor for production.
- Can we identify the country in which the asset was operated? In the worst case, we can assume that this is the same as the loading port, and assign a country average emission factor.
Conclusion
It can be challenging for companies to provide highly structured data for carbon footprinting. Thanks to machine learning, they don’t have to. We can take the data that customers have to hand and tame it, extracting the insights we need to provide accurate carbon footprints, even when data is imperfect. This reduces onboarding time and allows us to deliver insights quickly with minimal work on the client side.
If this has sparked your interest in what we’re building at CarbonChain, please get in touch!

1 An alternative we may explore in the future is to use subword embeddings. Very large language models trained on extensive web corpi have shown surprising success at representing real-world organizations.
